Point Location using Trapezoidal Maps

This problem is known as the
point location problem
and it is part of computational geometry. Like always in algorithmics, you try to solve
your problem with the algorithm that fits your context best. Trapezoidal Maps are fast to
construct O(n log n) and even faster in locating
corresponding areas to points O(log n). However,
the input of the algorithm is very specific and therefore Trapezoidal Maps are not always
suitable for every application. The Trapezoidal Map is one of many possible solutions to the
point location problem.
What did I do?
The main subject of my thesis was to describe and implement the algorithm that is used to construct the Trapezoidal Map and analyze its runtime. I implemented the algorithm into a framework that provided classes and geometry functions and a GUI to draw my output onto. This framework was written by my supervisor Dr. Fabian Stehn . The entire implementation of the algorithm and the framework was written in Java.
Trapezoidal Map?
As mentioned in the task, you are given the edges of a polygon or generally speaking: a set
of n line segments. The Trapezoidal Map is the
vertical decomposition of all given segments, which is obtained by drawing vertical extensions
through each endpoint of every segment. Let's say you want to construct a Trapezoidal Map from
the segments right here:
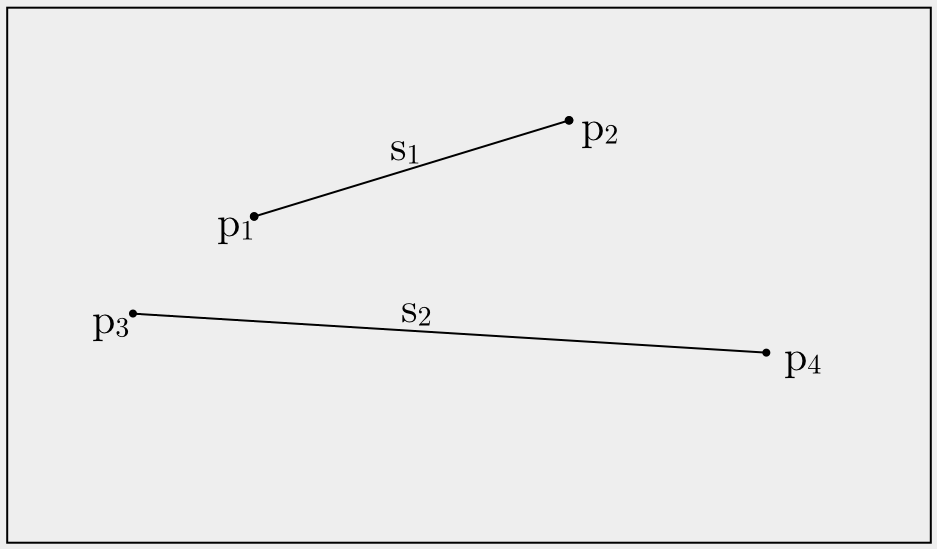
Initial Trapezoidal Map
Then the corresponding Trapezoidal Map looks like this:
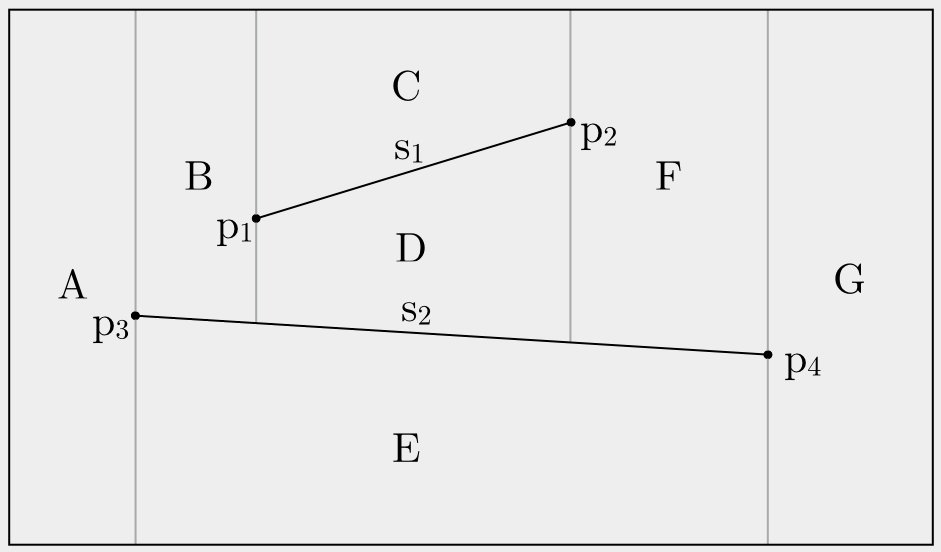
Final Trapezoidal Map
So, we draw vertical extensions through every endpoint of a segment until they cross another
segment or the bounding box. You can derive from this example that the Trapezoidal Map gets
its name from the resulting trapezoid-shaped faces A, B, C, D. Each face has two parallel sides.
How to get the face that contains my point?
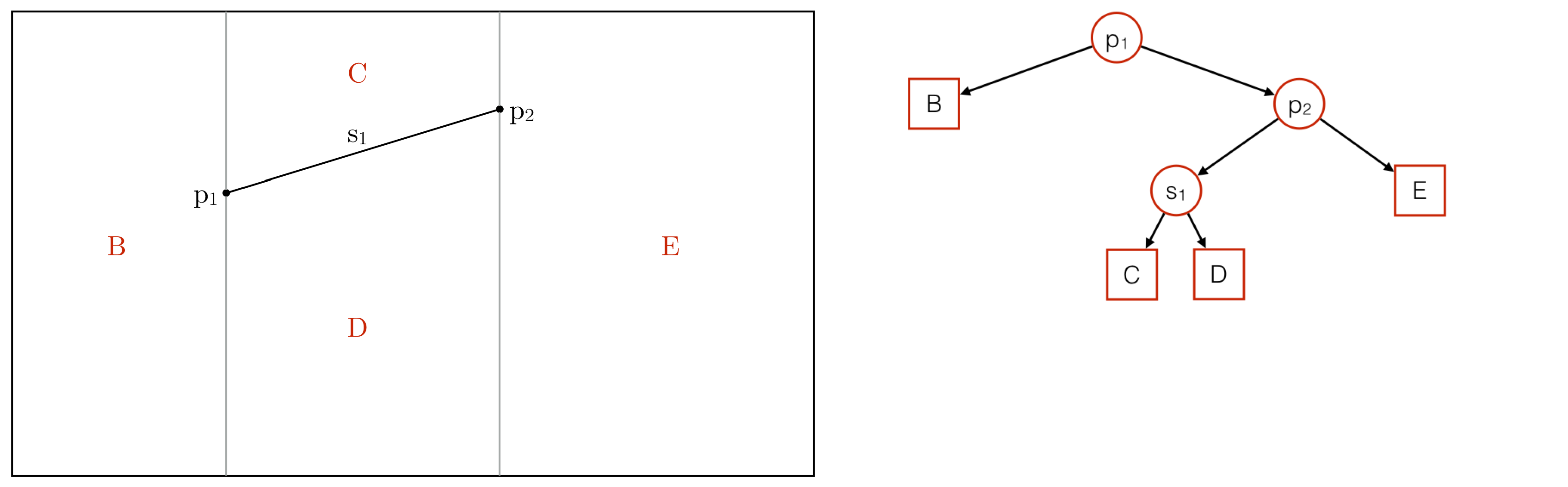
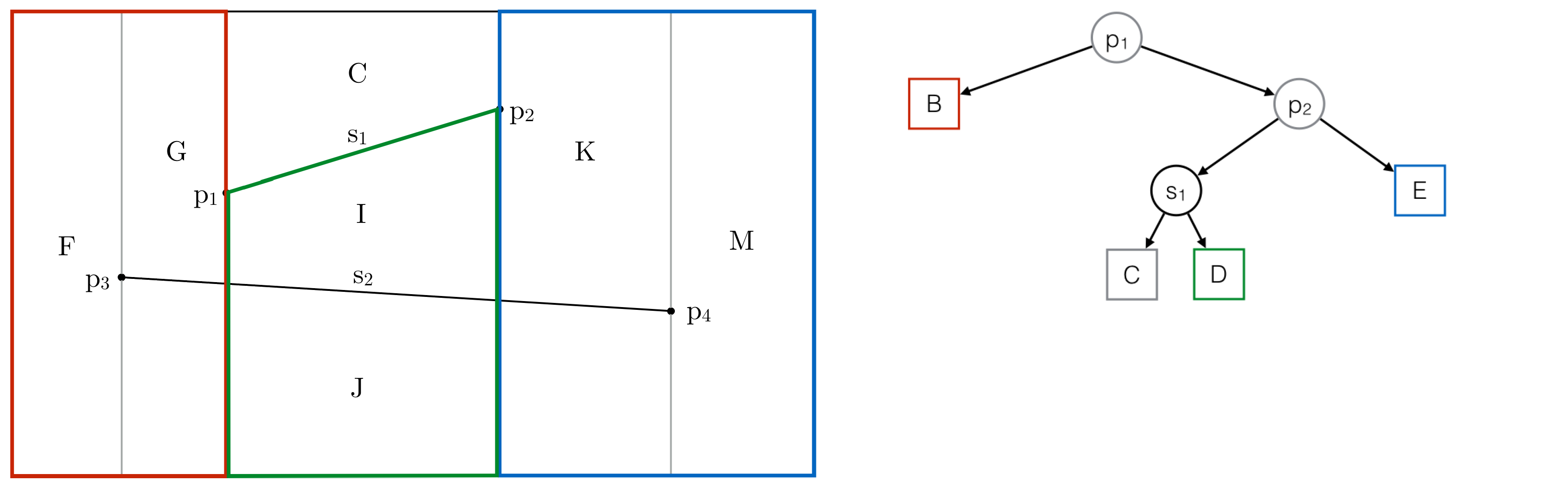
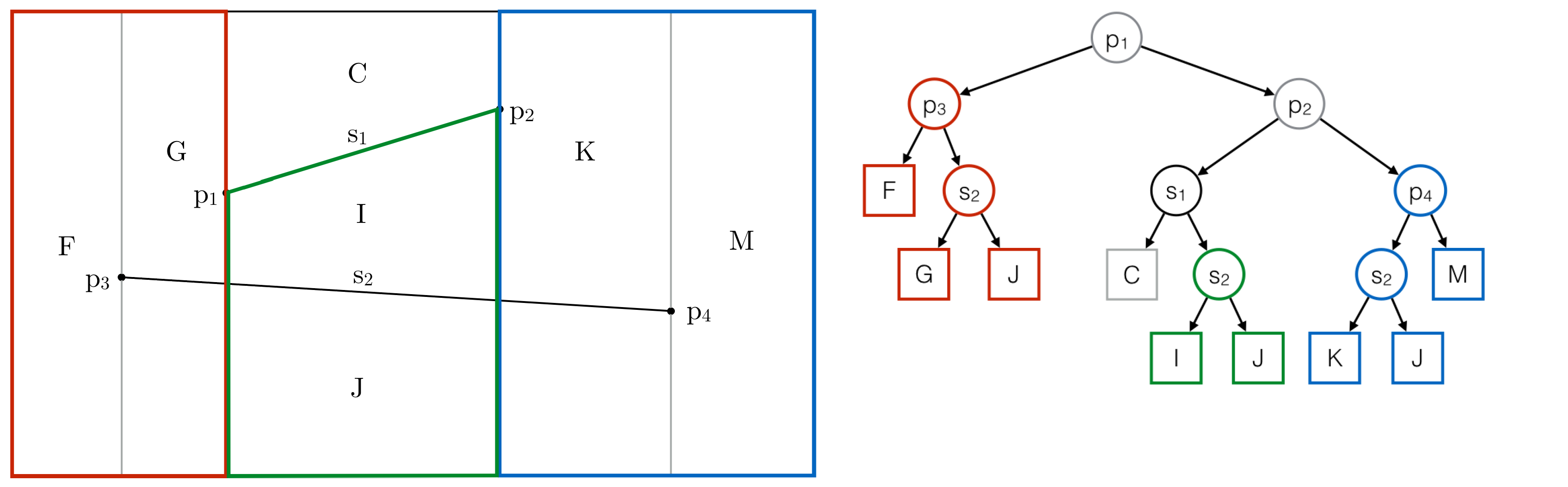
The Trapezoidal Map is dependent on an auxiliary data structure called History, an acyclic directed graph. It is a search structure that makes it possible to perform point queries. When you want to determine the area that contains a point, you give that point to the History and it returns the corresponding area. The History to the Trapezoidal Map from the example looks like this:
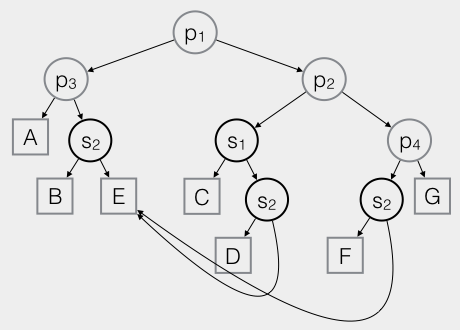
History Example
As you can see, the inner nodes of the History are labeled with points or segments of the Trapezoidal Map, while the leaves are labeled with trapezoids. In fact, the History contains three kinds of nodes:
- X-nodes: Inner node storing an endpoint of a segment
- Y-nodes: Inner node storing a segment
- Leaf-nodes: Representing trapezoids
A point query starts at the root node of the History and proceeds along inner nodes towards a leaf node storing the trapezoid in which our query point lies. Let's take an arbitrary point somewhere in the Trapezoidal Map and perform a point query with the History. The search begins at the root node. At every visited node the following questions are asked:
-
If the node is an x-node
- Does the query point lie to the left or to the right of the point stored in this x-node?
- It lies to the right: take the right child node
- It lies to the left: take the left child node
-
If the node is a y-node
- Does the query point lie above or below the segment stored in this y-node?
- It lies below: take the right child node
- It lies above: take the left child node
-
If the node is a leaf-node
- Return the trapezoid stored in this leaf-node
Using this set of questions, we can easily implement a recursive function that returns the trapezoid containing our point. The History graph structure is constructed while the Trapezoidal Map is created. There are multiple possible History structures for a Trapezoidal Map and vice versa. Finally, let's take a look at how to build the Trapezoidal Map and the History to make all this fancy stuff happen.
The randomized incremental algorithm for planar trapezoid construction
S of n non-crossing line
segments.
-
Determine a bounding box that contains every segment in
S. Initialize the Trapezoidal Map and the corresponding search structure for it. - Compute a random permutation of the elements in
S. - For
i = 1tondo: -
Find the set of trapezoids that are intersected when the segment
siis added. -
Remove the intersected trapezoids that arise because of the insertion of
si. - Remove the leaves for the intersected trapezoids from the search structure and create leaves for the new trapezoids. Link the created leaves to the existing nodes in the search structure.
Awesome.
As you can see, the first two steps are the initialization steps before the incremental
construction starts. We create a bounding box that is set to be our initial Trapezoidal Map and
initialize the History, which at this point is basically a graph with just one leaf-node that
represents the bounding box. After that, we permute the input set S randomly that contains all line segments. This
makes this algorithm a randomized algorithm, which is very important for the calculation of the
algorithm's runtime.
After the initialization steps, we start adding the line segments of S one by one to the Trapezoidal Map and update the History (incremental). To get a visual
perspective on how the loop works, take a look at those slides:

Step 1: Initialization of Trapezoidal Map and History

Step 4: First segment to be added
Step 6: Vertical extension of the segment
Step 6: The History is updated with new nodes for the new trapzoids
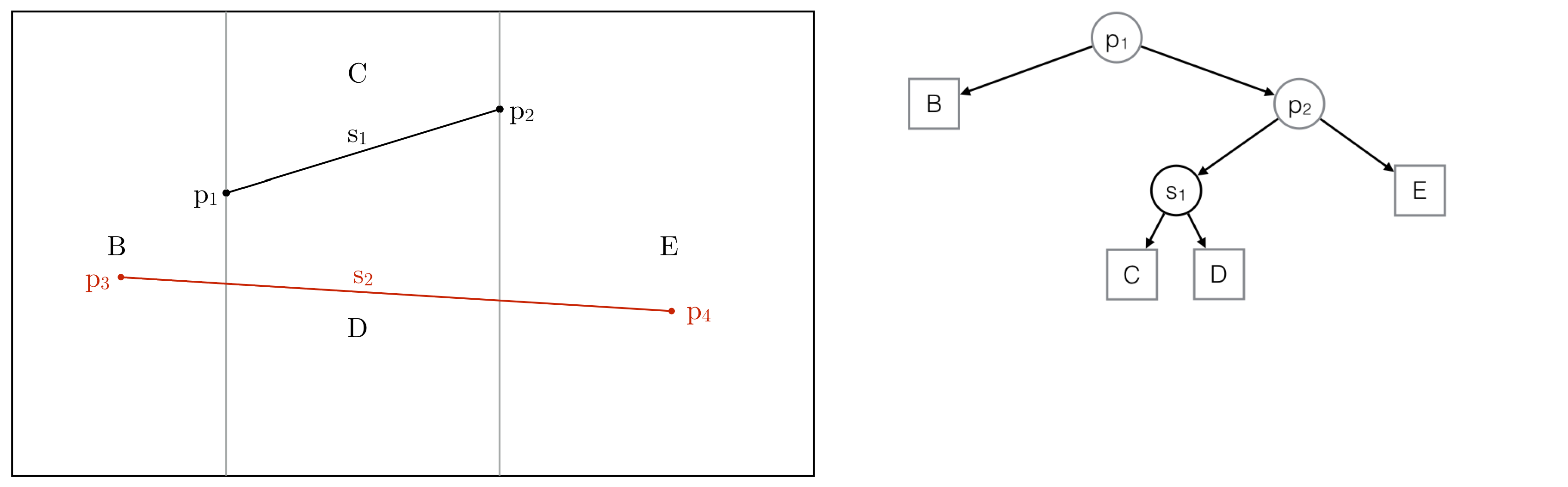
Step 4: Second segment to be added
Step 5: Intersected trapezoids are highlighted
Step 5: The first intersected trapezoid is replaced by three new trapezoids
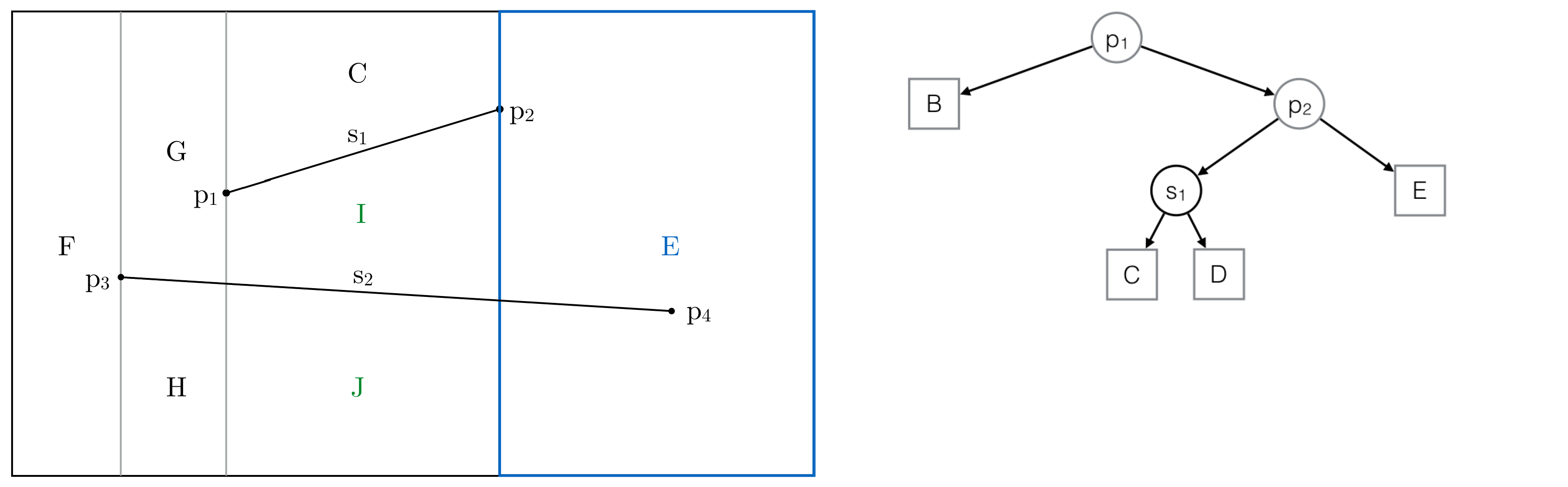
Step 5: The second intersected trapezoid is replaced by two new trapezoids
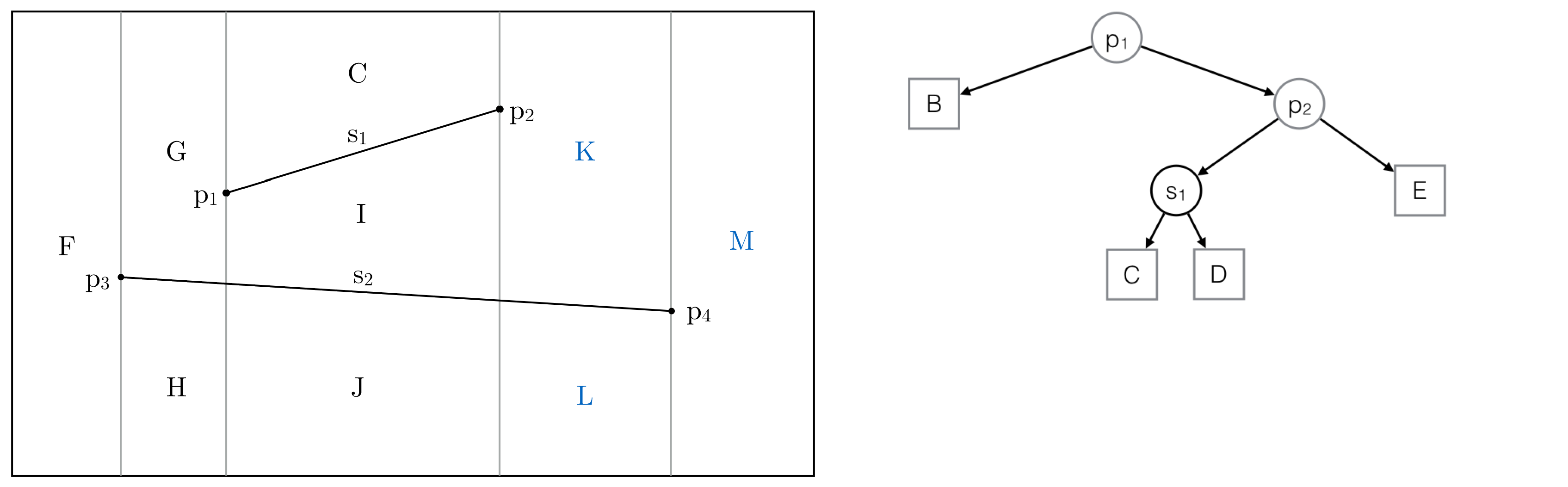
Step 5: The third intersected trapezoid is replaced by three new trapezoids
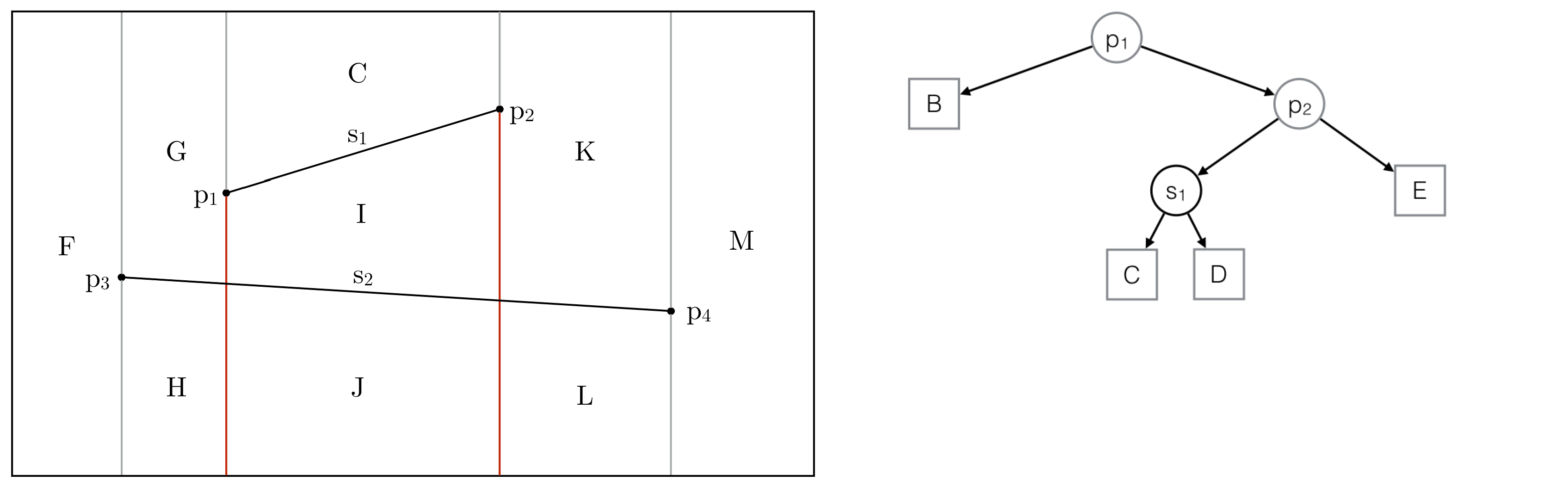
Step 5: Highlighted vertical extensions of the first segment are too long
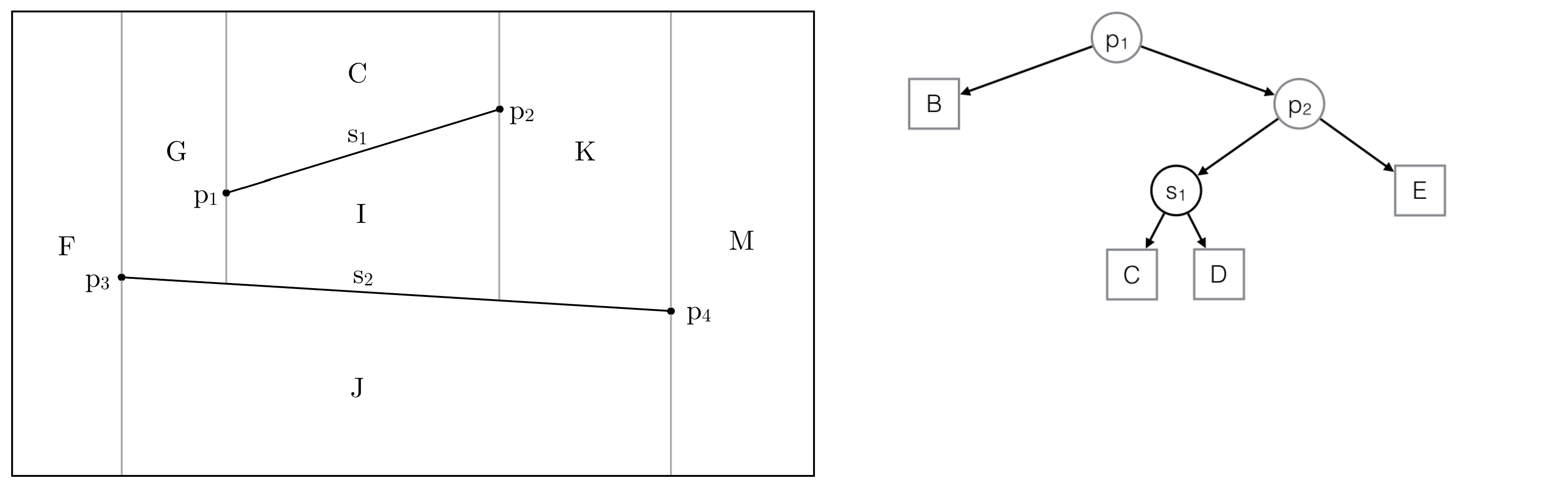
Step 5: Shortening of the vertical extensions
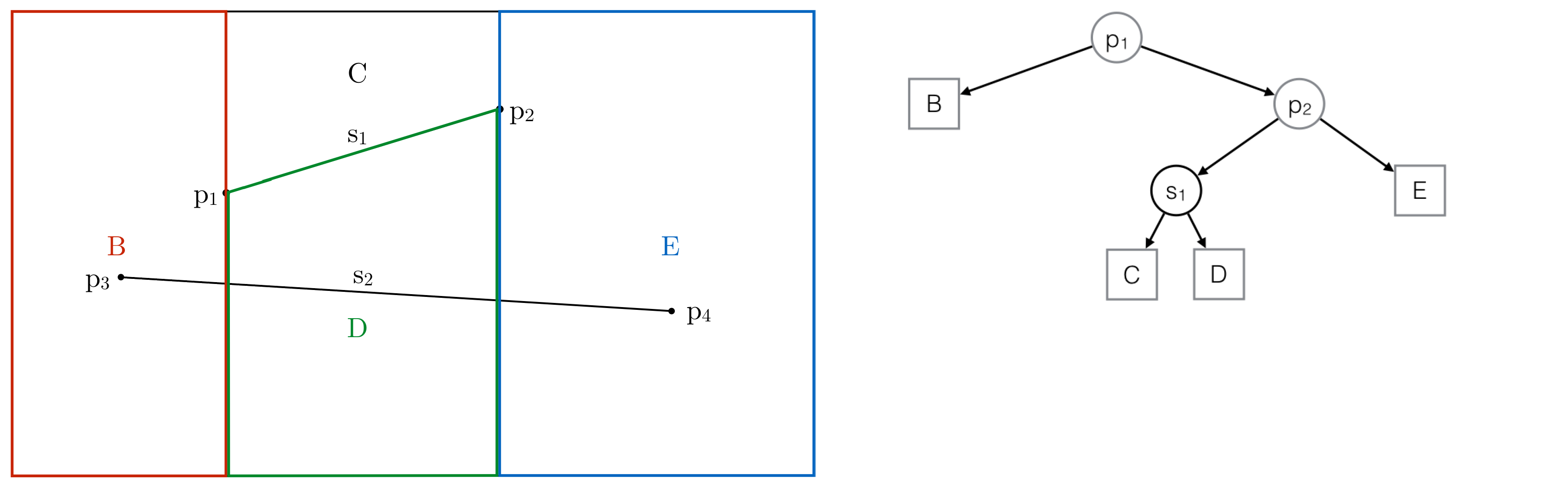
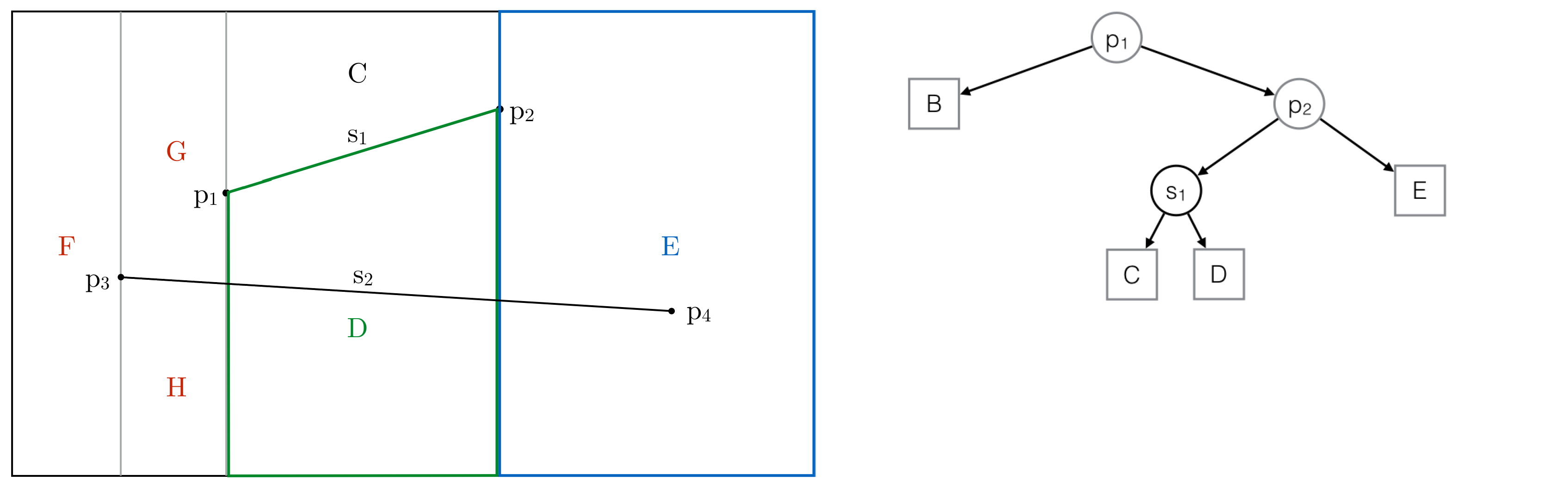
Intersected trapezoids are highlighted in the Trapezoidal Map and the History
Step 6: Nodes of intersected trapezoids are replaced by new ones
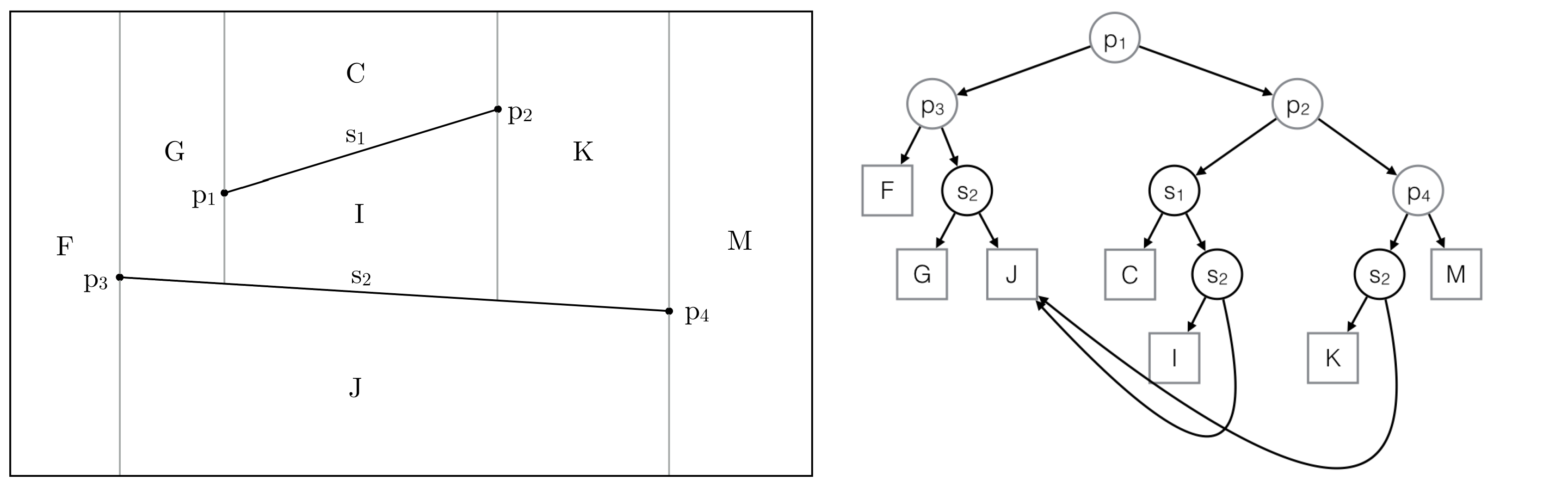
Same trapezoid nodes are linked together
Tools used
You have probably noticed that the description of this algorithm is very abstract, especially concerning the steps inside of the loop. While I was trying to implement a working version of this algorithm into the framework, I encountered many little problems to solve, I didn't even imagined to be there in the first place. The framework provided classes for points, segments and faces, geometry functions and a lot of other useful utility.
Because the framework was written in Java, I also used Java to implement the algorithm. I learned a lot about object-oriented programming, design patterns and the advantages of using them.
For the Trapezoidal Map I used a datastructure called Doubly-connected edge list (DCEL) , which is very useful when working with plane graphs. The greatest advantage is to be able to navigate through the graph. This is possible, because every element in the DCEL has links to neighbor elements. The Trapezoidal Map consists of points, segments and trapezoids, while the DCEL works with vertices, edges and face. Points become vertices, segments become successions of half-edges and trapezoids become faces. The framework provided a working DCEL implementation, but I had to rewrite a lot of functions for basic modifications like adding and removing an edge, splitting faces by edges, inserting vertices etc. Modifying the DCEL is tricky, because you have to ensure that every vertex, edge and face is linked correctly within the DCEL.
The output of the algorithm in the framework was a DCEL that represented the Trapezoidal Map, and a History class that could perform point queries. The implementation also provided an animation that showed how points were vertically extended, how segments were added, how the history was modified during construction and how a point query proceeds along the directed path through the History.
Runtime
When you analyze the runtime of an algorithm, the worst-case and the average-case scenario are of great interest. We use the Big-O notation among other things (memory usage, stability, etc.) to classify algorithms and express runtime scenarios. When we run an algorithm, we want to know how long the algorithm will approximately take to handle the input and generate the output. The Big-O notation tells us how the number of operations approximately grows when we increase the input. Here are some common classes of algorithm's running times in the order of growth:
O(1)- constant (no growth)O(log n)- logarithmic (very slow growth)O(n)- linearO(n log n)- linearithmic-
O(n2)- quadratic -
O(nx)- polynomial O(2^n)- exponential (fast growth)O(n!)- factorial (very fast growth)
Remember that these classifications are approximations of how the algorithm's operations grow when
we increase the number of input elements. When we calculate the runtime of our algorithm we might
end up with some O(3 + 4n + 37n log(n) + 2n2). This can
be reduced to O(n2) because it is the
term with the biggest growth.
In the case of the construction algorithm of the Trapezoidal Map, we can derive an expected runtime of O(n log n).
Performing a point query with the History takes an expected runtime of O(log n). That also means that if
we want to perform n point queries on a constructed Trapezoidal Map, we will have to expect a
runtime of O(n log n).
In the case of the construction algorithm, the n refers
to the number of line-segments we use.